Zeichenkodierungen (ISO-8859-Familie und andere)
![]() Die ISO-8859-Zeichenkodierungen
Die ISO-8859-Zeichenkodierungen
![]() Liste der ISO-8859-Zeichenkodierungen
Liste der ISO-8859-Zeichenkodierungen
![]() Alle offiziellen Zeichenkodierungen
Alle offiziellen Zeichenkodierungen
Zeichenkodierungen (ISO-8859-Familie und andere) |
|
|
|
|
| | |
Die ISO-8859-Familie wurde vom European Computer Manufacturer's Association (ECMA) entwickelt. Es handelt sich um ein Set von standardisierten Zeichenkodierungen für alphabetische Schriften. Dazu gehören die lateinischen Schriften, auf denen die meisten Sprachen Westeuropas und Amerikas beruhen, oder etwa die kyrillischen Schriften.
Alle Kodierungen dieser Familie basieren auf der Speicherung eines Zeichens mit genau einem Byte. Das heißt, die Codetabellen, auf denen diese Kodierungen aufbauen, enthalten 256 mögliche Zeichen. Bei allen Codetabellen sind die ersten 128 Zeichen, also die Zeichen mit den Werten 0 bis 127, identisch mit der ASCII-Codetabelle. Das hat den Vorteil, dass die üblichen lateinischen Groß- und Kleinbuchstaben, die arabischen Ziffern und die üblichen Sonderzeichen wie Satzzeichen oder kaufmännische Zeichen bei diesen Kodierungen immer zur Verfügung stehen.
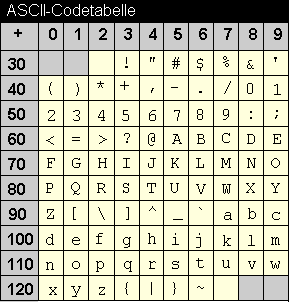
Oberhalb sind die darstellbaren Zeichen der ASCII-Codetabelle abgebildet. Diese Zeichen haben die Werte zwischen 32 und 126. Wert 32 ist das Leerzeichen. Alle ISO-8859-Codetabellen enthalten diesen Codes.
Den Wert eines Zeichens, auch Codenummer genannt, ermitteln Sie, indem Sie die Werte aus Spalten- und Zeilenüberschrift des Zeichens addieren. Ein großes K hat in dieser Tabelle beispielsweise den Zeilenwert 70 und den Spaltenwert 5. Daraus ergibt sich der Wert 75 für dieses Zeichen. Falls Sie nicht den Dezimalwert eines Zeichens benötigen, sondern den Hexadezimalwert, können Sie den ![]() Dezimal/Hexadezimal-Umrechner benutzen.
Dezimal/Hexadezimal-Umrechner benutzen.
So wie in der ASCII-Codetabelle die ersten 32 Zeichen (Zeichenwerte 0 bis 31) und das Zeichen 127 für Steuerzeichen reserviert sind, sparen auch die erweiterten Codetabellen der ISO-8859-Kodierungen einen Bereich von Zeichen aus. Es handelt sich um die ersten 32 Zeichen oberhalb des ASCII-Bereichs, also um die Zeichenwerte 128 bis 159. Die Tabellen zu den einzelnen Kodierungen weiter unten bilden daher die verbleibenden Zeichenwerte 160 bis 255 ab. Das Zeichen mit dem Wert 160 ist in all diesen Tabellen ein erzwungenes Leerzeichen.
Viele der Codetabellen der ISO-8859-Kodierungen überlappen sich. Das ist Absicht. Die Kodierungen sind so optimiert, dass sich mit einer möglichst alle Zeichen möglichst vieler Schriften speichern lassen. Zeichen, die in mehreren Codetabellen der ISO-8859-Kodierungen vorkommen, haben in der Regel immer den gleichen Wert, d.h. sie befinden sich in den unterschiedlichen Codetabellen an der gleichen Stelle.
Sechs der ISO-8859-Kodierungen beziehen sich auf Schriften, die im Kern auf der lateinischen Schrift basieren. Diese Kodierungen haben daher die Beinamen Latin-1 bis Latin-6.
![]()
![]()
Die folgenden Tabellen zeigen die einzelnen Codetabellen der ISO-8859-Kodierungen. Wenn Sie diese Kodierungen in HTML einsetzen möchten, benötigen Sie einen HTML-Editor, der Ihnen das Speichern der HTML-Datei mit eben diesen Kodierungen ermöglicht. Zusätzlich sollten Sie eine![]() Meta-Angabe zur Zeichenkodierung nicht vergessen. Die blau dargestellten Namen sind jene Bezeichnungen, die Sie in einer solchen Kodierungsangabe notieren können.
Meta-Angabe zur Zeichenkodierung nicht vergessen. Die blau dargestellten Namen sind jene Bezeichnungen, die Sie in einer solchen Kodierungsangabe notieren können.
Die Codetabelle dieser Kodierung enthält die schriftspezifischen Zeichen für westeuropäische und amerikanische Sprachen. Der Zeichenvorrat deckt die Sprachen Albanisch, Dänisch, Deutsch, Englisch, Färöisch, Finnisch, Französisch, Galizisch, Irisch, Isländisch, Italienisch, Katalanisch, Niederländisch, Norwegisch, Portugiesisch, Schwedisch und Spanisch ab. Lediglich einzelne Zeichen wie das niederländische ij, die französischen Ligaturen œ und Œ oder die deutschen Anführungszeichen „“ fehlen.
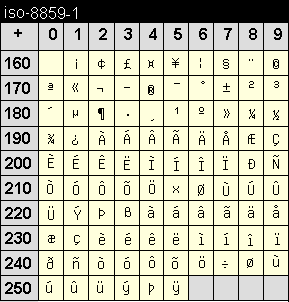
Die Codetabelle dieser Kodierung enthält die schriftspezifischen Zeichen für die meisten mitteleuropäischen und slawischen Sprachen. Sie deckt die Sprachen Kroatisch, Polnisch, Rumänisch, Slowakisch, Slowenisch, Tschechisch und Ungarisch ab.
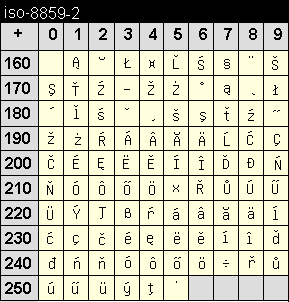
Die Codetabelle dieser Kodierung deckt die Sprachen Esperanto, Galizisch, Maltesisch und Türkisch ab.
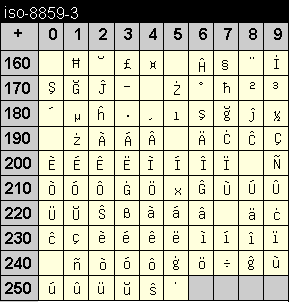
Die Codetabelle dieser Kodierung enthält einige Zeichen der Sprachen Estnisch, Lettisch und Litauisch. Vergleichen Sie diese Kodierung auch mit ISO 8859-10, deren Codetabelle sehr ähnlich ist.
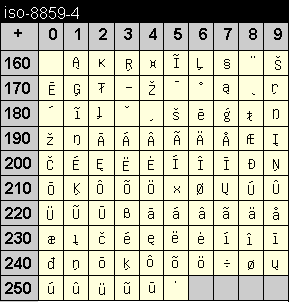
Die Codetabelle dieser Kodierung enthält kyrillische Zeichen. Sie deckt weitgehend die Sprachen Bulgarisch, Mazedonisch, Russisch, Serbisch und Ukrainisch ab.
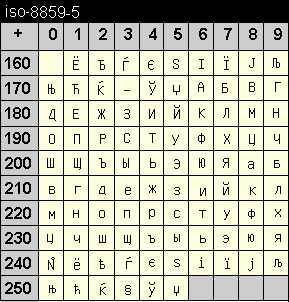
Die Codetabelle dieser Kodierung enthält Zeichen arabischer Schrift. Die Darstellung der Zeichen in der folgenden Tabelle ist jedoch "abstrakt", da die Zeichen in der Schriftpraxis variieren, je nachdem, ob sie am Anfang, in der Mitte oder am Ende eines Wortes oder einzeln stehen. Arabisch zeichnet sich weiterhin dadurch aus, dass die Schriftrichtung von rechts nach links ist.
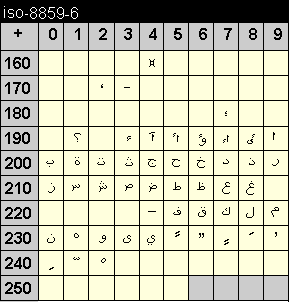
Die Codetabelle dieser Kodierung enthält die Zeichen der neugriechischen Schrift.
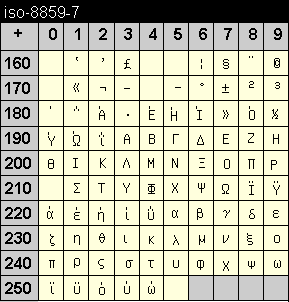
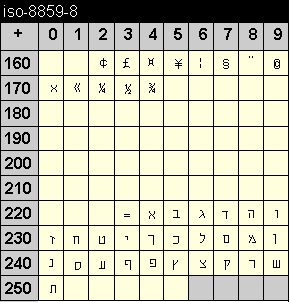
Die Codetabelle dieser Kodierung enthält die Zeichen der hebräischen Schrift. Wie bei der arabischen Schrift ist dabei die Schriftrichtung von rechts nach links.
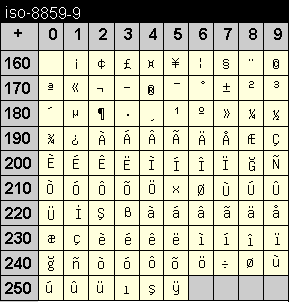
Diese Kodierung ist speziell für Türkisch gedacht. Die Codetabelle basiert auf ISO 8859-1, enthält jedoch anstelle der isländischen Sonderzeichen türkische Zeichen.
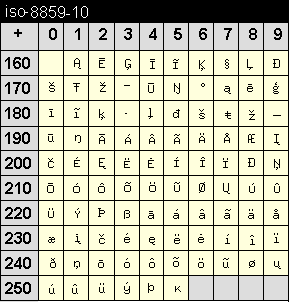
Die Codetabelle dieser Kodierung enthält speziell Zeichen für die Sprachen Grönländisch (Inuit) und Lappisch (Sami).
![]()
![]()
Es gibt etliche andere, zum Teil schon ältere Kodierungen, die Konventionen für einzelne Schriften oder Schriftfamilien definieren, häufig landesspezifisch. Unter der folgenden Web-Adresse werden die Namen dieser Kodierungen gesammelt:
![]() http://www.iana.org/assignments/character-sets
http://www.iana.org/assignments/character-sets
Diejenigen Kodierungsnamen, die dort in der Liste jeweils hinter Name: oder Alias: aufgelistet sind, können Sie in HTML in der ![]() Meta-Angabe zur verwendeten Zeichenkodierung verwenden. Bevorzugt sollten Sie jene Namen verwenden, die in der Liste mit dem Zusatz
Meta-Angabe zur verwendeten Zeichenkodierung verwenden. Bevorzugt sollten Sie jene Namen verwenden, die in der Liste mit dem Zusatz preferred MIME name gekennzeichnet sind.
|
| |
© 2005 ![]() Impressum
Impressum